Esta clase de infraestructura es utilizada comúnmente por cualquier compañía que posee un elevado tráfico de datos y necesita ofrecer un conjunto de servicios con unas garantías mínimas de fiabilidad. Imaginemos por un momento la cantidad de peticiones que puede recibir Google a lo largo de un minuto, y pensemos también que conlleva dicha petición: procesarla a través de un servidor web, acceder a una base de datos, realizar una o varias consultas, devolver una serie de resultados, etc. En resumen, una única máquina sería incapaz de realizar todo este proceso individualmente debido al enorme caudal de conexiones y tareas involucradas.
¿Qué es lo que se hace entonces? Acudir al viejo lema de "divide y vencerás". Por un lado se tendrán varias máquinas que exclusivamente se encargarán de atender las conexiones. A continuación, esas peticiones se repartirán (Balanceo de Carga) a distintos servidores web en función de su carga de trabajo. Y por último, estos servidores realizarán las consultas apropiadas a una base de datos distribuida y ubicada en diferentes nodos. Y todo ello garantizando la continuidad del servicio (Alta Disponibilidad), es decir, si alguno de los elementos de la cadena falla, el sistema global seguiría funcionando correctamente y este hecho sería imperceptible para el usuario.
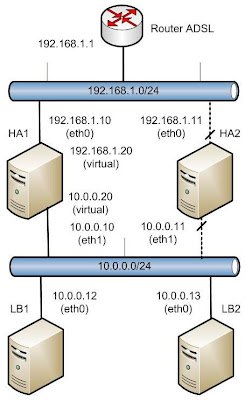
En el esquema de red que se va a desarrollar, se va a configurar un sistema de Alta Disponibilidad mediante Heartbeat, y Balanceo de Carga a través de de ldirectord. La máquina HA1 será el nodo activo, encargado de recibir las peticiones a través de la dirección IP virtual 192.168.1.20 y repartirlas a los dos servidores, LB1 y LB2, empleando para ello la otra dirección IP virtual, 10.0.0.20. En caso de caída de HA1 (se apaga la máquina, se reinicia, pierde el link en su interfaz de red, etc), HA2 levantará las dos direcciones virtuales en sus interfaces de red, pasando en este momento a ser el nodo activo. Si HA1 se vuelve a recuperar, HA2 pasará a ser nuevamente el nodo pasivo (quitará las direcciones virtuales de sus interfaces de red).
Para la base de datos, se utilizará un sistema MySQL Cluster en los nodos LB1 y LB2, siendo HA1 y HA2 los nodos de administración del cluster. Los nodos de almacenamiento serán LB1 y LB2, los cuales tendrán una base de datos compartida y replicada en ambas máquinas, de tal forma que lo que se escriba en una, también se trasladará a la otra. Para aumentar el rendimiento del sistema, MySQL Cluster almacenará la base de datos en memoria.
El proceso encargado de la administración del cluster MySQL residirá en HA1 (nodo activo). En caso de caída de HA1, HA2 levantará dicho demonio de administración. Si se cae uno de los dos nodos de almacenamiento, cuando se vuelva a recuperar sincronizará automáticamente el contenido de su base de datos con la del otro nodo que seguía levantado.
En los dos nodos traseros (LB1 y LB2) también se configurará un servicio web (Apache2) y FTP (vsftpd). En consecuencia, será necesario establecer un área de datos compartida, de forma que los directorios utilizados por Apache y vsftpd sean idénticos en ambas máquinas. Tenemos que pensar que estamos ante un sistema totalmente transparente de cara al usuario: HA1 repartirá peticiones que podrán ser tratadas indistintamente por cualquiera de los dos nodos traseros, es decir, el espacio de almacenamiento de ambos servicios (web y FTP) deberá ser común para ambas máquinas, con lo que si una de ellas graba un dato dentro de este espacio, la otra tenga acceso instantáneo al mismo.
Para configurar todo este entramado, se montará un directorio común en los dos nodos traseros de tipo RAID1 (espejo) mediante GlusterFS, de manera que todo lo que se escriba en uno, se verá automáticamente reflejado en el otro, y viceversa.
De cara a monitorizar periódicamente el estado de los servicios configurados se utilizará el demonio mon. Si alguno de dichos servicios cae, mon podrá tomar distintas medidas así como enviar alertas por email.
También será necesario dotar de una cierta protección a la infraestructura que se va a levantar. Para proteger los puertos del sistema que queden abiertos hacia el exterior, se utilizará la herramienta iptables, de tal forma que se establecerá como política por defecto para todos los paquetes que lleguen a las máquinas (cadena INPUT), la opción de denegar, y se dejarán abiertos aquellos puertos utilizados por los distintos servicios.
Y por último, para que los dos nodos frontales puedan redirigir paquetes hacia los nodos traseros (habilitar el flujo de datos entre los distintos interfaces de red), activaremos el ip_forward en HA1 y HA2. Y para que el sistema funcione correctamente, todos los nodos deberán estar sincronizados horariamente. Para ello cada 60 minutos, se sincronizará la hora de cada máquina mediante un servidor horario externo.

Saludo cordiales, deseo seguir informándome acerca de los presentes y futuros artículos del autor
ReplyDeleteLos artículos que presenta el autor son de suma importancia para una trabajo de investigación sobre redes virtuales en entornos distribuidos, por lo que solicito ller todo lo publicado por el autor en mi email albertoguerra26@yahoo.es , espero los envios correspondientes, gracias
ReplyDeletePor lo que entiendo vas a balancear trafico de peticiones que llegan a un servidor web (Apache). Pero, ¿se podría aprovechar el mismo mecanismo para balancear tráfico de otro tipo de servicios? Es decir, ¿y si la información que se comparte entre los servidores LB1 y LB2 no estuviera almacenada en ficheros (páginas html), sino que es información que se mantiene en memoria RAM? El articulo tiene muy buena pinta. Voy a ver si los artículos que siguen a este responden a mis preguntas!
ReplyDelete1) Puedes balancear cualquier tipo de servicio. En LVS configuras el puerto (servicio), el algoritmo de balanceo de carga y los nodos.
Delete2)Siempre podrás montar una martición directamente en memoria RAM y utilizar herramientas como GlusterFS o DRBD para compartir ese área entre todos los nodos.
hola amigos muy inetresante el tema q exponen tengo una consulta tengo un cliente q quiere hacer balanceo de carga de consultas de 3 server q paresen ser identicos ¿pregunta puedo hacer el trabajo de H1 y h2 CON ROUTER MIKROTIK?
ReplyDeleteY SI PUDIERA ¿QUE SERVICIOS BASICOS DEBO TENER EN MIS ROUTER?